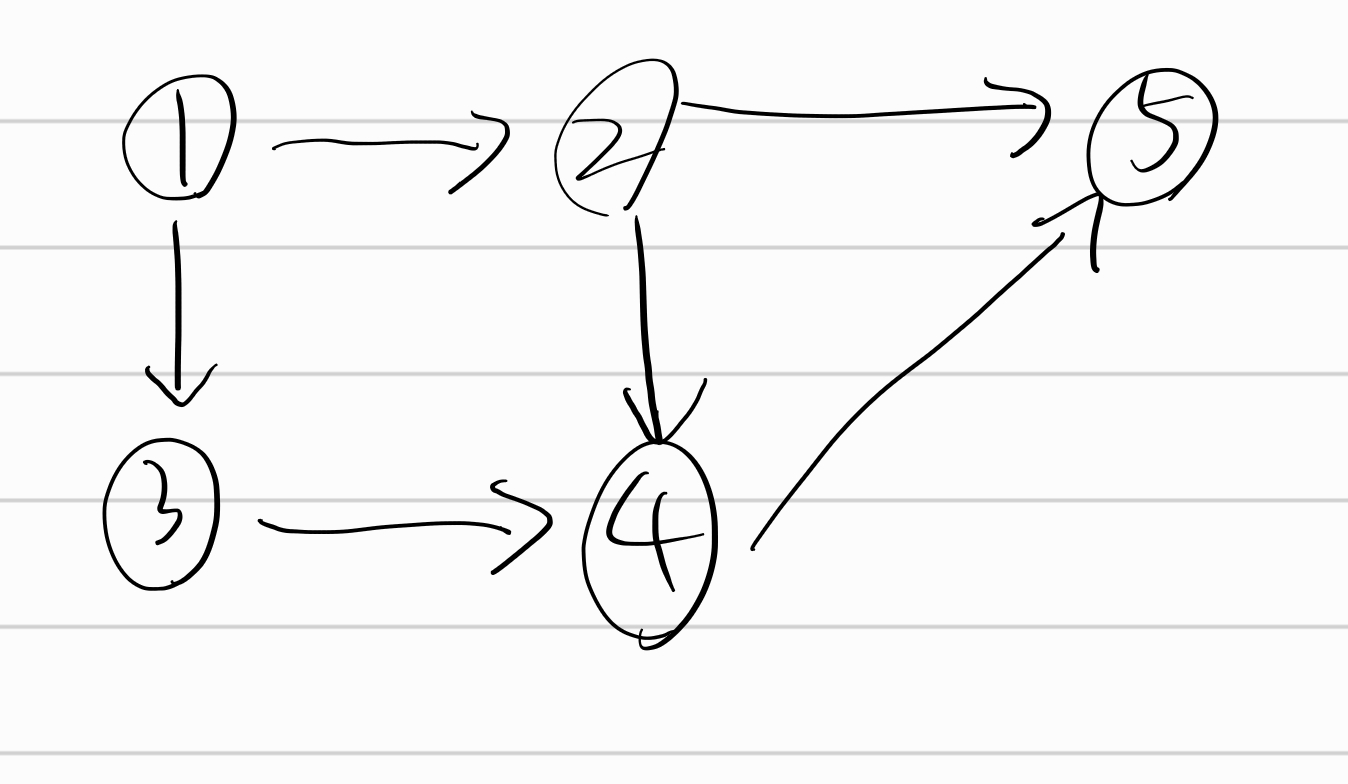
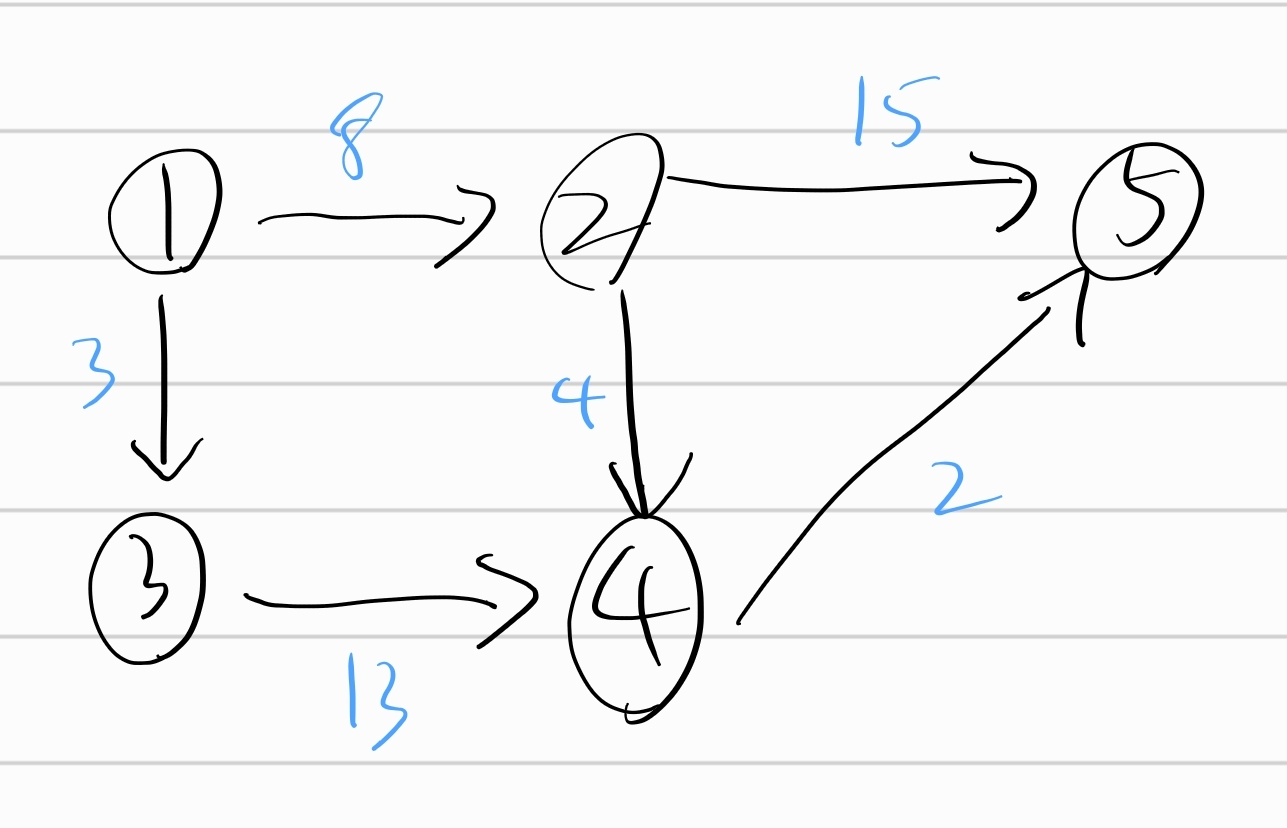
그래프는 노드와 엣지로 구성된 집합이다. 노드는 데이터를 표현하는 단위이고 엣지는 노드를 연결한다.
엣지 리스트
엣지를 중심으로 그래프를 표현한다. 배열에 출발 노드, 도착 노드를 저장하여 엣지를 표현하는데 여기에 가중치를 표함하는 경우도 있다.
엣지 리스트로 가중치가 없는 그래프 표현
가중치가 없다면 출발 노드와 도착 노드만 표현하니까 배열의 행은 2개면 충분하다.
1 2 3 4 5 6
[1,2] [1,3] [3,4] [2,4] [2,5] [4,5]
1 -> 2 로 나가는 엣지를 [1,2] 로 표현한다. 이렇게 방향이 있는 그래프는 순서에 맞게 노드를 배열에 저장하는 방식으로 표현한다.
노드를 배열에 저장하여 엣지를 표현하니까 엣지 리스트라고 부른다.
(방향이 없는 그래프라면 [1,2]와 [2,1]은 같은 표현이 될 수 있다.)
ArrayList[1]에 [(2,8), (3,3)] 이 연결되어 있다. 이는 노드1과 가중치8 엣지로 노드 1과 3이 가중치 3 엣지로 연결되어 있다는 걸 보여주고 방향성도 알수 있다.
인접 리스트를 이용한 그래프 구현은 다른 방법들에 비해 복잡한 편이지만
노드와 연결되어 있는 엣지를 탐색하는 시간은 뛰어나며, 노드 개수가 커도 공간 효율이 좋아 메모리 초과 에러도 발생하지 않는다.
그래서 많은 코딩 테스트에서는 인접 리스트를 이용한 그래프 구현을 선호한다.
Spring에서 Bean들은 Spring Container에 의해서 싱글톤으로 관리되는데 이는 애플리케이션에 한개의 인스턴스만 존재하는데 여러 Thread가 동시에 접근할 경우 동시성 이슈가 발생할 수 있는데 이를 해결하기 위해 Java에서는 ThreadLocal 객체를 활용할 수 있다.
ThreadLocal은 Thread만 접근가능한 저장소로 여러 Thread가 접근할 경우 각각의 Thread를 식별해서 저장소를 구분한다. 따라서 같은 인스턴스의 ThreadLocal 필드에 여러 Thread가 접근하더라도 상관이 없다.
get(), set(), remove() 같은 메서드를 통해 조회, 저장, 저장소를 초기화한다.
톰캣과 같은 WAS에선 Thread Pool을 만들고 Request가 들어오면 각 Thread가 해당 요청을 담당하여 프로세스를 처리한다.
Spring Boot가 실행되면 내부적으로 ThreadPoolExecutor 구현체를 생성해서 내장 톰캣이 사용할 Thread Pool을 생성하는 구조
Thread Pool 을 사용하는 환경에선 Thread Pool을 통해 Thread가 재사용될 수 있으므로 사용이 끝나면 명시적으로 초기화를 해줘야 한다.
ThreadPoolExecutor를 확장해서 beforeExecute()와 afterExecute() 메서드에서 이러한 문제들을 해결할 수 있다.
기존 서블릿 기반의 Spring Boot는 Tomcat을 기본 Embeded WAS로 사용하는데 WebFlux의 경우 Netty를 기본으로 사용한다.
Tomcat은 요청 당 하나의 Thread가 동작하지만 Netty는 1개의 이벤트를 받는 Thread와 다수의 Worker Thread로 동작하게 된다.
Netty는 channel에서 발생하는 이벤트를 EventLoop가 처리하는 구조로 동작하는데 EventLoop는 이벤트를 실행하기 위한 무한루프 Thread라고 볼수 있다.