[WebFlux] map과 flatMap에 대해서
spring WebFlux를 사용하다보면 체인 연산자로 FlatMap을 사용해야할지, Map을 사용해야할지 헷갈리는 경우가 있어서 정리해봤다.
map 함수
public final
Flux map(Function<? superT,? extends V> mapper)
- Transform the items emitted by this Flux by applying a synchronous function to each item.
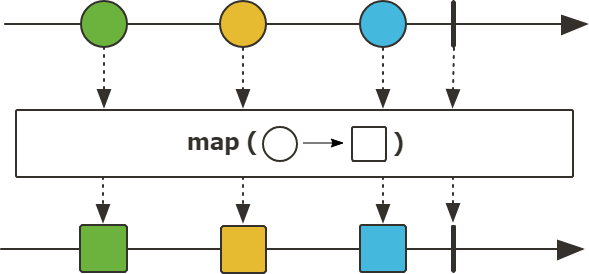
map 함수는 데이터 스트림의 각 요소를 변환하는데 사용되는 함수로 각 요소를 동기적으로 처리하며, 각 요소를 변환하여 새로운 데이터 스트림을 반환한다.
간단한 샘플코드를 보자.
1 |
|
Function mapper는 스트림을 구독할 때 실행되며 각 요소의 순서를 유지하며 입력값을 변환하여 새로운 값으로 출력하게 된다.
flatMap 함수
public final
Flux flatMap(Function<? superT,? extendsPublisher<? extends V>> mapper, int concurrency)
- Transform the elements emitted by this Flux asynchronously into Publishers, then flatten these inner publishers into a single Flux through merging, which allow them to interleave.
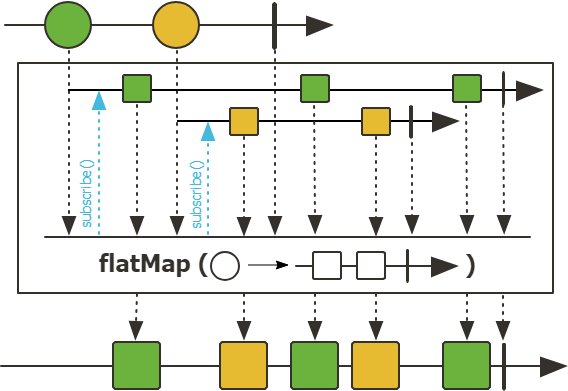
flatMap 함수는 데이터 스트림의 각 요소별로 publisher를 생성하여 여러개의 하위 스트림이 생성되고 subscribe를 통해 단일 스트림으로 묶은 Publisher로 반환한다.
이러한 Publisher를 비동기적으로 처리하여 순서를 보장하지 않기 때문에 순서를 보장하고 싶으면 flatMapSequential 이나 concatMap 등을 사용할 수 있다.
샘플코드를 보자.
1 |
|
mapper에서 Publisher로 반환되는데 별도의 스레드를 할당하고 flatMap에서 비동기로 동작하게 되면서 순서를 보장하지 않는 flatMap의 응답값은 apple, banana, carrot의 글자가 섞이게 된다.
사용 시 고려사항
map은 각 요소가 1:1로 매핑되서 동기적으로 처리된다.
flatMap은 각 요소에 대해서 1:다 매핑이 되서 단일 스트림으로 병합되고 publisher의 동작에 따라서 동기적, 혹은 비동기적으로 동작할 수 있다.
단순히 DTO 객체변환이라든지, 단일요소에 대한 간단한 계산같은건 map을 사용하면 좋고 각 요소의 처리 시간이 다를 수 있는 작업이나 외부 서비스, DB 호출 등의 작업을 할때는 비동기 동작이 가능한 flatMap을 사용하는게 좋다.
map은 단일 데이터 스트림의 각 요소를 독립적으로 처리하기 때문에 요소의 크기에 따라 성능차이가 크진 않지만 flatMap은 데이터 스트림을 개별적으로 처리 후 병합하기 위해 데이터 스트림의 크기나 작업량에 따라서 성능적으로 영향이 map에 비해서 상대적으로 클 수 있다.