Spring에서 Bean들은 Spring Container에 의해서 싱글톤으로 관리되는데 이는 애플리케이션에 한개의 인스턴스만 존재하는데 여러 Thread가 동시에 접근할 경우 동시성 이슈가 발생할 수 있는데 이를 해결하기 위해 Java에서는 ThreadLocal 객체를 활용할 수 있다.
ThreadLocal은 Thread만 접근가능한 저장소로 여러 Thread가 접근할 경우 각각의 Thread를 식별해서 저장소를 구분한다. 따라서 같은 인스턴스의 ThreadLocal 필드에 여러 Thread가 접근하더라도 상관이 없다.
get(), set(), remove() 같은 메서드를 통해 조회, 저장, 저장소를 초기화한다.
톰캣과 같은 WAS에선 Thread Pool을 만들고 Request가 들어오면 각 Thread가 해당 요청을 담당하여 프로세스를 처리한다.
Spring Boot가 실행되면 내부적으로 ThreadPoolExecutor 구현체를 생성해서 내장 톰캣이 사용할 Thread Pool을 생성하는 구조
Thread Pool 을 사용하는 환경에선 Thread Pool을 통해 Thread가 재사용될 수 있으므로 사용이 끝나면 명시적으로 초기화를 해줘야 한다.
ThreadPoolExecutor를 확장해서 beforeExecute()와 afterExecute() 메서드에서 이러한 문제들을 해결할 수 있다.
기존 서블릿 기반의 Spring Boot는 Tomcat을 기본 Embeded WAS로 사용하는데 WebFlux의 경우 Netty를 기본으로 사용한다.
Tomcat은 요청 당 하나의 Thread가 동작하지만 Netty는 1개의 이벤트를 받는 Thread와 다수의 Worker Thread로 동작하게 된다.
Netty는 channel에서 발생하는 이벤트를 EventLoop가 처리하는 구조로 동작하는데 EventLoop는 이벤트를 실행하기 위한 무한루프 Thread라고 볼수 있다.
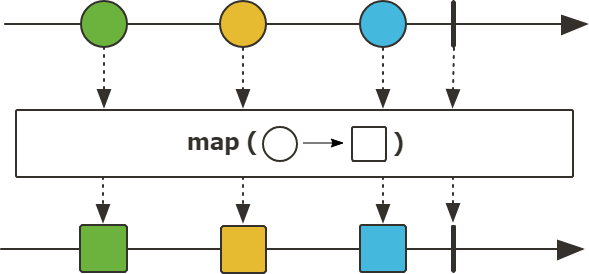
Function mapper는 스트림을 구독할 때 실행되며 각 요소의 순서를 유지하며 입력값을 변환하여 새로운 값으로 출력하게 된다.
flatMap 함수
public final Flux flatMap(Function<? superT,? extendsPublisher<? extends V>> mapper, int concurrency)
Transform the elements emitted by this Flux asynchronously into Publishers, then flatten these inner publishers into a single Flux through merging, which allow them to interleave.
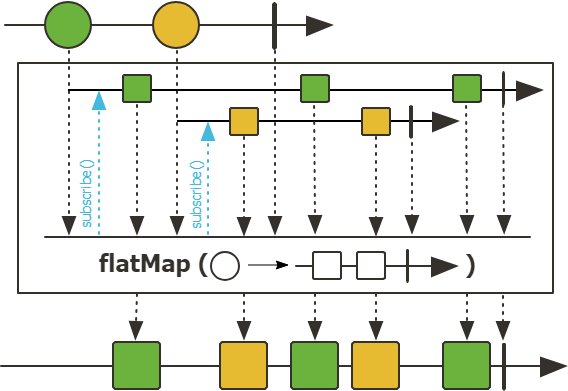
flatMap 함수는 데이터 스트림의 각 요소별로 publisher를 생성하여 여러개의 하위 스트림이 생성되고 subscribe를 통해 단일 스트림으로 묶은 Publisher로 반환한다.
이러한 Publisher를 비동기적으로 처리하여 순서를 보장하지 않기 때문에 순서를 보장하고 싶으면 flatMapSequential 이나 concatMap 등을 사용할 수 있다.
mapper에서 Publisher로 반환되는데 별도의 스레드를 할당하고 flatMap에서 비동기로 동작하게 되면서 순서를 보장하지 않는 flatMap의 응답값은 apple, banana, carrot의 글자가 섞이게 된다.
사용 시 고려사항
map은 각 요소가 1:1로 매핑되서 동기적으로 처리된다.
flatMap은 각 요소에 대해서 1:다 매핑이 되서 단일 스트림으로 병합되고 publisher의 동작에 따라서 동기적, 혹은 비동기적으로 동작할 수 있다.
단순히 DTO 객체변환이라든지, 단일요소에 대한 간단한 계산같은건 map을 사용하면 좋고 각 요소의 처리 시간이 다를 수 있는 작업이나 외부 서비스, DB 호출 등의 작업을 할때는 비동기 동작이 가능한 flatMap을 사용하는게 좋다.
map은 단일 데이터 스트림의 각 요소를 독립적으로 처리하기 때문에 요소의 크기에 따라 성능차이가 크진 않지만 flatMap은 데이터 스트림을 개별적으로 처리 후 병합하기 위해 데이터 스트림의 크기나 작업량에 따라서 성능적으로 영향이 map에 비해서 상대적으로 클 수 있다.
Mono.defer()와 Mono.fromCallable() 모두 지연 평가(lazy evaluation)를 제공하는데 사용된다. 지연 평가란 호출 시점을 지연시켜서 필요한 시점에서 코드를 실행하는 방식을 의미한다.
Mono.defer() 메서드는 Mono의 factory 메서드 중 하나로, 인자로 전달받은 Supplier 함수를 사용하여 Mono 객체를 생성한다. 이때 Supplier 함수가 호출되는 시점은 Mono 객체를 subscribe 할 때이다.
Mono.fromCallable() 메서드는 Mono의 factory 메서드 중 하나로, 인자로 전달받은 Callable 함수를 사용하여 Mono 객체를 생성한다. 이때 Callable함수가 호출되는 시점은 Mono객체 생성 시점이다.
따라서 Mono.defer()는 Mono 객체를 생성할 때마다 Supplier함수를 실행하여 객체를 생성하는 방식을 사용하며, Mono.fromCallable()은 Mono객체를 생성하는 시점에서 Callable함수를 실행하여 객체를 생성하는 방식을 사용한다. Mono.fromCallable()은 즉시 실행되므로, Mono.defer()보다 더 많은 자원을 소비할 수 있다.
Mono.defer()는 Mono의 객체 생성 시점을 늦추고, 객체 생성과 동시에 상태를 초기화할 수 있는 장점이 있고 반면에 Mono.fromCallable()은 Callable함수의 실행 결과를 즉시 Mono객체에 포함시키므로, 결과를 즉시 필요로 하는 경우에 유용하다.
privatestatic Mono<?> callExternalService() { System.out.println("External service is called."); return Mono.just("result"); }
/* External service is called. result result result result */
Mono.just(“result”)의 결과를 repeat(3)으로 세 번 반복하게 되면, 해당 Mono를 세 번 실행하게 된다.
하지만, Mono.just(“result”)는 호출될 때마다 값을 생성하는 게 아니라, 최초 1회 호출시 생성한 값을 계속해서 방출하게 된다. 그래서 "External service is called."는 처음 1회만 출력되고, 세 번 반복되는 Mono.just(“result”)는 이미 생성된 값을 방출하게 되므로, 추가로 호출할 필요가 없어지게 된다.
따라서 "External service is called."는 최초 1회만 출력되고, 세 번 반복되는 Mono.just(“result”)는 이미 생성된 값을 방출하게 된다.
BiFunction<Integer, Integer, Integer> accumulator = (a, b) -> a + b; Mono<Integer> sum = numbers.reduce(0, accumulator);
sum.subscribe(result -> System.out.println("The sum of the numbers is: " + result)); } }
This example creates a Flux of integers and then uses the reduce method to sum them up. The reduce method takes an initial value, in this case 0, and a BiFunction that specifies how the current accumulation (a) is combined with each element from the flux (b) to produce the next accumulation.
The subscribe method is then used to subscribe to the Mono returned by reduce and print out the result.
initial Type is HashMap
Here’s an example of how you could use the reduce method with an initial value of a HashMap:
This example creates a Flux of strings and uses the reduce method to count the occurrences of each word. The reduce method takes an initial value, in this case a new empty HashMap, and a BiFunction that specifies how the current HashMap (map) is combined with each word from the flux (word) to produce the next HashMap.
The subscribe method is then used to subscribe to the Mono returned by reduce and print out the result.
Why does Mono<HashMap<String, Integer>> wordCounts = words.reduce(Collections.emptyMap(), accumulator); error occur?
The error occurs because Collections.emptyMap() returns an unmodifiable map, which means you can’t modify it. The reduce method expects the accumulator function to modify the accumulator object, which is not possible with an unmodifiable map.
You can resolve the issue by creating a new empty HashMap as the initial value instead of using Collections.emptyMap(), like this:
This will give you a modifiable map that can be updated by the accumulator function as required by the reduce method.
But why does Java Stream API succeed?
The Java Stream API allows you to use the reduce method with an initial value of Collections.emptyMap() because the reduce operation in the Stream API operates on an internal data structure that is separate from the original data source. This allows the Stream API to handle unmodifiable maps as the initial value without any issues.
However, in reactive programming with Spring WebFlux, the reduce method operates on the data stream directly, so you need to provide an accumulator object that is mutable. That’s why you need to use a new empty HashMap instead of Collections.emptyMap() as the initial value.
별로 기대하지 않았는데 원하는 내용에 대해서 생각보다 정확한 답변을 들을 수 있었다.
먼저 Flux의 reduce 호출 시initial가 HashMap인 케이스로 샘플코드를 요청하고 Collections.emptyMap() 을 초기값으로 사용 시 왜 오류가 나는지 물어봤고
Collections.emptyMap()으로 생성되는 객체는 returns an unmodifiable map 즉, immutable(불변)객체인데 reduce 메서드는 초기값으로 들어온 accumulator 객체를 수정할 것으로 예상했지만 수정이 불가능한 불변객체가 들어와서 오류가 발생하는거라고 한다.
Stream의 reduce에선 왜 성공하는지? 에 대해선
Stream의 reduce는 원래 데이터와는 다른 별도의 내부 데이터 구조에서 동작하기 때문에 Collections.emptyMap()의 초기값으로 reduce를 사용할 수 있지만
리액티브 프로그래밍 기반의 WebFlux에선 데이터 스트림에서 reduce 메서드가 직접 동작하기 때문에 변경가능한 accumulator 객체를 제공해야 하므로 변경이 가능한 빈 HashMap 객체를 생성해야 한다고 답변하였다.
앞으로 나의 코딩선생님이 하나 더 늘었다는 생각에 흥분되면서도 한편으론 chatGPT를 사용해서 구글의 코딩인터뷰 Level3도 통과했다는 뉴스처럼 문맥을 파악해서 의도한 바를 정확하게 알려주는 답변을 보고 소름이 돋았다.