이 코드는 Booking과 Payment 같은 타입과 기존 아이템의 상태코드 값을 받아서 매칭되는 상태값을 반환하는 메서드였다. 코드는 처음에 보면 별 생각이 없었지만, 타입 유형이 늘어나고 코드가 많아지면 switch문이 복잡해지고 유지보수가 어려워지는 문제가 생길 수 있다고 생각이 들었다.
검색을 하던 도중 시간이 좀 지난 글이지만 우아한형제들 기술블로그 - Java Enum 활용기 라는 글에서 3. 데이터 그룹관리 세션의 내용을 적용할 수 있겠다고 판단되었다. Enum을 활용하여 데이터를 그룹화 하고 각 타입은 본인이 수행해야할 기능만 책임지도록 하는게 중요해 보였다.
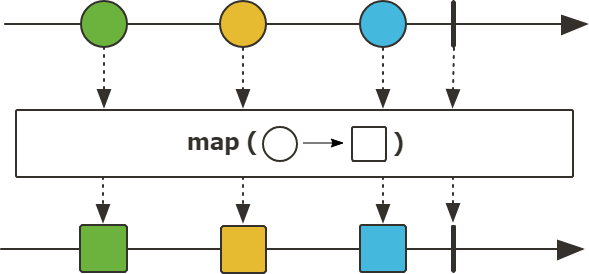
Function mapper는 스트림을 구독할 때 실행되며 각 요소의 순서를 유지하며 입력값을 변환하여 새로운 값으로 출력하게 된다.
flatMap 함수
public final Flux flatMap(Function<? superT,? extendsPublisher<? extends V>> mapper, int concurrency)
Transform the elements emitted by this Flux asynchronously into Publishers, then flatten these inner publishers into a single Flux through merging, which allow them to interleave.
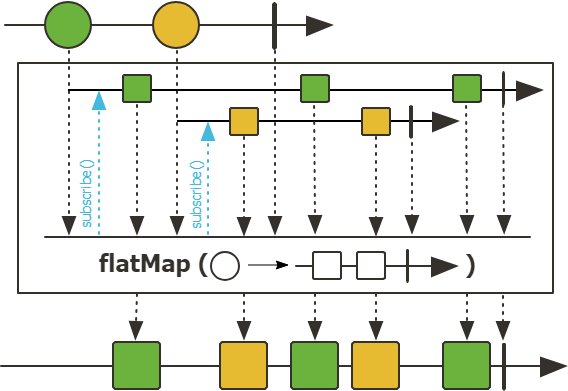
flatMap 함수는 데이터 스트림의 각 요소별로 publisher를 생성하여 여러개의 하위 스트림이 생성되고 subscribe를 통해 단일 스트림으로 묶은 Publisher로 반환한다.
이러한 Publisher를 비동기적으로 처리하여 순서를 보장하지 않기 때문에 순서를 보장하고 싶으면 flatMapSequential 이나 concatMap 등을 사용할 수 있다.
mapper에서 Publisher로 반환되는데 별도의 스레드를 할당하고 flatMap에서 비동기로 동작하게 되면서 순서를 보장하지 않는 flatMap의 응답값은 apple, banana, carrot의 글자가 섞이게 된다.
사용 시 고려사항
map은 각 요소가 1:1로 매핑되서 동기적으로 처리된다.
flatMap은 각 요소에 대해서 1:다 매핑이 되서 단일 스트림으로 병합되고 publisher의 동작에 따라서 동기적, 혹은 비동기적으로 동작할 수 있다.
단순히 DTO 객체변환이라든지, 단일요소에 대한 간단한 계산같은건 map을 사용하면 좋고 각 요소의 처리 시간이 다를 수 있는 작업이나 외부 서비스, DB 호출 등의 작업을 할때는 비동기 동작이 가능한 flatMap을 사용하는게 좋다.
map은 단일 데이터 스트림의 각 요소를 독립적으로 처리하기 때문에 요소의 크기에 따라 성능차이가 크진 않지만 flatMap은 데이터 스트림을 개별적으로 처리 후 병합하기 위해 데이터 스트림의 크기나 작업량에 따라서 성능적으로 영향이 map에 비해서 상대적으로 클 수 있다.
WARN YAMLException: please see https://github.com/hexojs/hexo/issues/4917 FATAL TypeError: Cannot read property 'length' of undefined at composeNode (D:\workspace\blog\node_modules\hexo\node_modules\js-yaml\lib\loader.js:1492:60) at composeNode (D:\workspace\blog\node_modules\hexo\node_modules\js-yaml\lib\loader.js:1441:12) at readDocument (D:\workspace\blog\node_modules\hexo\node_modules\js-yaml\lib\loader.js:1625:3) at loadDocuments (D:\workspace\blog\node_modules\hexo\node_modules\js-yaml\lib\loader.js:1688:5) at Object.load (D:\workspace\blog\node_modules\hexo\node_modules\js-yaml\lib\loader.js:1714:19) at Hexo.yamlHelper (D:\workspace\blog\node_modules\hexo\lib\plugins\renderer\yaml.js:20:15) at Hexo.tryCatcher (D:\workspace\blog\node_modules\bluebird\js\release\util.js:16:23) at Hexo.<anonymous> (D:\workspace\blog\node_modules\bluebird\js\release\method.js:15:34) at D:\workspace\blog\node_modules\hexo\lib\hexo\render.js:81:22 at tryCatcher (D:\workspace\blog\node_modules\bluebird\js\release\util.js:16:23) at Promise._settlePromiseFromHandler (D:\workspace\blog\node_modules\bluebird\js\release\promise.js:547:31) at Promise._settlePromise (D:\workspace\blog\node_modules\bluebird\js\release\promise.js:604:18) at Promise._settlePromise0 (D:\workspace\blog\node_modules\bluebird\js\release\promise.js:649:10) at Promise._settlePromises (D:\workspace\blog\node_modules\bluebird\js\release\promise.js:729:18) at _drainQueueStep (D:\workspace\blog\node_modules\bluebird\js\release\async.js:93:12) at _drainQueue (D:\workspace\blog\node_modules\bluebird\js\release\async.js:86:9) at Async._drainQueues (D:\workspace\blog\node_modules\bluebird\js\release\async.js:102:5) at Immediate.Async.drainQueues [as _onImmediate] (D:\workspace\blog\node_modules\bluebird\js\release\async.js:15:14) at processImmediate (internal/timers.js:464:21)
??? 뭐야 갑자기 왜…
당황했지만 일단 에러 로그에서 들어가보라고 나온 github issue 를 들어가보니 비슷한 오류에 대해서 이미 많은 토론이 진행되어 있었다.
6.1.0 버전으로 올렸을때 이런 이슈가 발생했고(2,3 도 비슷한듯) 해결책은 크게 두가지 였는데
6.0.0 으로 다운그레이드
js-yaml 을 4.1.0 으로 업그레이드
이와 별개로 현재 사용중인 icarus 테마도 지원하는 버전이 있을거라고 생각해서 들어가보니 5.0.1 버전에서 hexo 6에 대한 언급이 있어서 이참에 최신버전으로 올렸다.
일단 위 내용들을 고려해서 6.0.0 으로 다운그레이드를 시도 했고 다시 실행해보니 정상적으로 실행되었다.
1 2
npm i hexo@6.0.0 hexo s
아직 의문인 점은 6.3.0 버전에서 설치되는 js-yaml은 분명 4.1.0 인데 서버 실행 시 오류가 발생하고 6.0.0으로 한번 내렸다가 다시 6.3.0 으로 올리면 정상적으로 실행된다는 점이다 … ㅎㅎ;;
INFO Validating config Inferno is in development mode. INFO ======================================= ██╗ ██████╗ █████╗ ██████╗ ██╗ ██╗███████╗ ██║██╔════╝██╔══██╗██╔══██╗██║ ██║██╔════╝ ██║██║ ███████║██████╔╝██║ ██║███████╗ ██║██║ ██╔══██║██╔══██╗██║ ██║╚════██║ ██║╚██████╗██║ ██║██║ ██║╚██████╔╝███████║ ╚═╝ ╚═════╝╚═╝ ╚═╝╚═╝ ╚═╝ ╚═════╝ ╚══════╝ ============================================= INFO === Checking package dependencies === INFO === Checking theme configurations === WARN Theme configurations failed one or more checks. WARN Icarus may still run, but you will encounter unexcepted results. WARN Here is some information for you to correct the configuration file. WARN [ { keyword: 'const', dataPath: '.widgets[7].type', schemaPath: '#/properties/type/const', params: { allowedValue: 'profile' }, message: 'should be equal to constant' }, ... ... ]
로그로 봤을땐 테마의 위젯 설정값이 뭔가 잘못된거 같길래 한참 이것저것 검색하다가 위젯 설정값을 찬찬히 보니까 type의 값을 주석처리 해놔서 발생한 오류였다.
진짜 이거 찾느라 시간 보낸거 아까워서 ㅠㅠ 나처럼 바보짓 하는 사람 없길 바라면 적는다.
1 2 3 4 5 6 7
-# Where should the widget be placed, left sidebar or right sidebar position:left type:#adsense # AdSense client ID client_id:"" # AdSense AD unit ID slot_id:""
작업들을 하면서 느끼는건데 Jekyll을 사용해서 샘플로 만들어봤을때 너무 느린 속도가 싫어서 Hexo를 선택했는데 포스팅한 글을 git으로 동시관리가 안되고 별도 repo 설정해서 이중관리 해야하는 부분이나 영어보다 중국어 레퍼런스가 더 많아서 관련 자료 찾는데 쉽지 않은 부분 때문에 요즘엔 다른 엔진으로 갈아타는건 어떨까 하는 생각도 든다.
일단 블로그 글도 별로 없는데 이런거 고민할 필요는 없을거 같기도 하고 ㅋㅋㅋ 나중에 다시 생각해보자
Mono.defer()와 Mono.fromCallable() 모두 지연 평가(lazy evaluation)를 제공하는데 사용된다. 지연 평가란 호출 시점을 지연시켜서 필요한 시점에서 코드를 실행하는 방식을 의미한다.
Mono.defer() 메서드는 Mono의 factory 메서드 중 하나로, 인자로 전달받은 Supplier 함수를 사용하여 Mono 객체를 생성한다. 이때 Supplier 함수가 호출되는 시점은 Mono 객체를 subscribe 할 때이다.
Mono.fromCallable() 메서드는 Mono의 factory 메서드 중 하나로, 인자로 전달받은 Callable 함수를 사용하여 Mono 객체를 생성한다. 이때 Callable함수가 호출되는 시점은 Mono객체 생성 시점이다.
따라서 Mono.defer()는 Mono 객체를 생성할 때마다 Supplier함수를 실행하여 객체를 생성하는 방식을 사용하며, Mono.fromCallable()은 Mono객체를 생성하는 시점에서 Callable함수를 실행하여 객체를 생성하는 방식을 사용한다. Mono.fromCallable()은 즉시 실행되므로, Mono.defer()보다 더 많은 자원을 소비할 수 있다.
Mono.defer()는 Mono의 객체 생성 시점을 늦추고, 객체 생성과 동시에 상태를 초기화할 수 있는 장점이 있고 반면에 Mono.fromCallable()은 Callable함수의 실행 결과를 즉시 Mono객체에 포함시키므로, 결과를 즉시 필요로 하는 경우에 유용하다.
privatestatic Mono<?> callExternalService() { System.out.println("External service is called."); return Mono.just("result"); }
/* External service is called. result result result result */
Mono.just(“result”)의 결과를 repeat(3)으로 세 번 반복하게 되면, 해당 Mono를 세 번 실행하게 된다.
하지만, Mono.just(“result”)는 호출될 때마다 값을 생성하는 게 아니라, 최초 1회 호출시 생성한 값을 계속해서 방출하게 된다. 그래서 "External service is called."는 처음 1회만 출력되고, 세 번 반복되는 Mono.just(“result”)는 이미 생성된 값을 방출하게 되므로, 추가로 호출할 필요가 없어지게 된다.
따라서 "External service is called."는 최초 1회만 출력되고, 세 번 반복되는 Mono.just(“result”)는 이미 생성된 값을 방출하게 된다.