6. 영속성 어댑터 구현하기
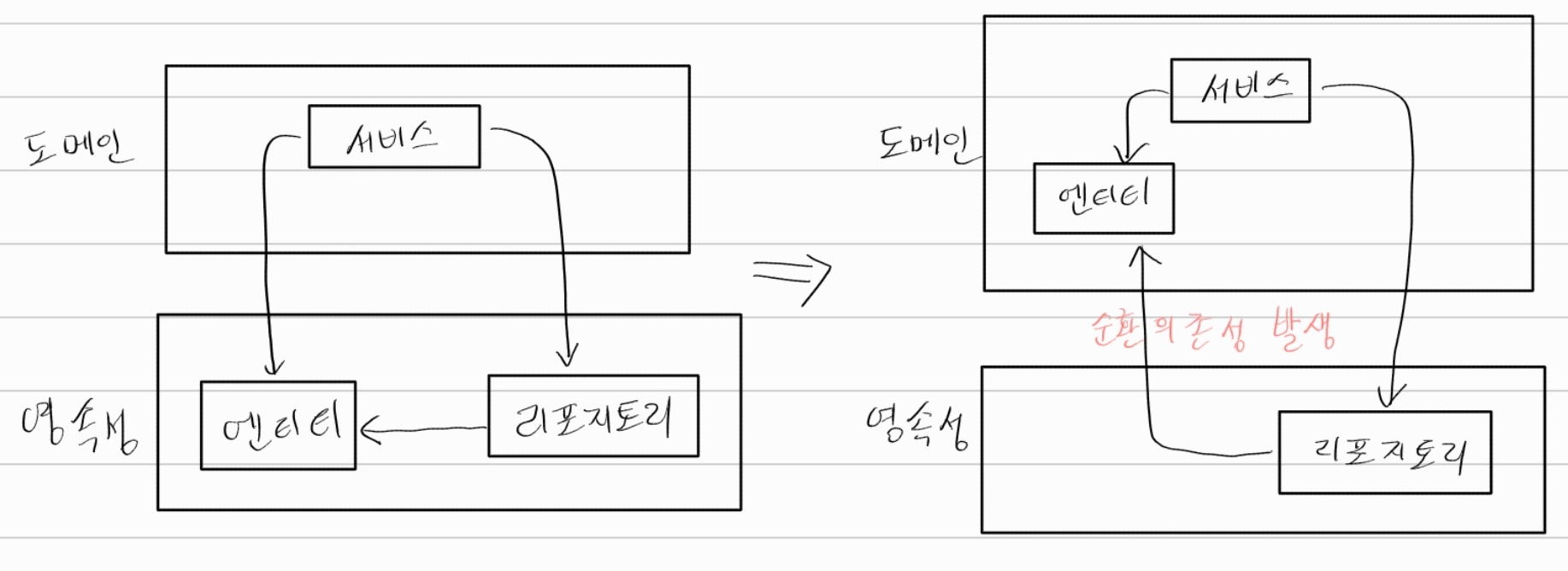
전통적인 계층형 아키텍처에서는 결국 모든 것이 영속성 계층에 의존하게 되어 ‘데이터베이스 주도 설계’가 되는 문제가 있다.
이러한 의존성을 역전시키기 위해 영속성 계층을 애플리케이션 계층의 플러그인으로 만드는 방식으로 구현해야 한다.
의존성 역전
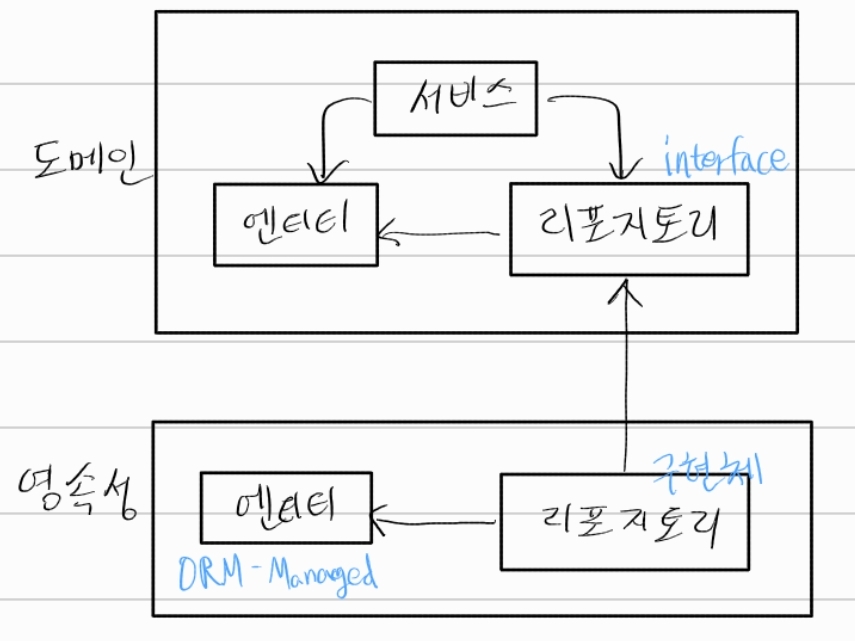
애플리케이션 서비스에서는 영속성 기능을 사용하기 위해 포트 인터페이스를 호출한다.
육각형 아키텍처에서 영속성 어댑터는 아웃고잉 어댑터이다. 애플리케이션에 의해 호출뿐, 애플리케이션을 호출하진 않기 때문이다.
포트는 애플리케이션 서비스와 영속성 코드 사이의 간접적인 계층으로 영속성 계층에 대한 코드 의존성을 없애기 위해 이러한 간접 계층이 추가되었다.
이제 영속성 코드를 리팩토링하더라도 코어 코드를 변경하는 결과로 이어지진 않는다.
영속성 어댑터의 책임
영속성 어댑터가 하는 일은 보통 아래와 같다.
- 입력을 받는다
- 데이터베이스 포맷으로 매핑
- 입력을 데이터베이스로 보낸다
- 데이터베이스 출력을 애플리케이션 포맷으로 매핑
- 출력을 반환한다.
중요한건 영속성 어댑터의 입력 모델이 영속성 어댑터 내부가 아닌 애플리케이션 코어에 있기 때문에 영속성 어댑터 내부를 변경하는 것이 코어에 영향을 미치지 않는다는 점이다.
출력 모델도 동일하게 애플리케이션 코어에 위치해야 한다.
포트 인터페이스 나누기
보통 특정 엔티티가 필요로 하는 모든 데이터베이스 연산을 하나의 리포지토리 인터페이스에 넣는 식으로 구현한다.
하지만 이러한 방식은 코드에 불필요한 의존성이 생기게 되는데 데이터베이스 연산에 의존하는 각 서비스는 인터페이스에 단 하나의 메서드나 사용하더라도 ‘넓은’ 포트 인터페이스에 의존성을 갖게 되는 문제가 발생한다.
맥락 상 필요하지 않는 메서드에 생긴 의존성은 코드를 이해하고 테스트하기 어렵게 만든다.
인터페이스 분리 원칙(Interface Segregation Principle, ISP)을 적용하여 클라이언트가 오직 자신이 필요로 하는 메서드만 알게 만들어 각각의 특화된 인터페이스로 분리해야 한다.
이렇게 되면 각 서비스는 실제로 필요한 메서드에만 의존하고, 포트의 이름은 역할을 명확하게 표현할 수 있으며 서비스 코드를 짤 때 필요한 포트에 연결만 하면 된다.
영속성 어댑터 나누기
위에서 나눈 포트 인터페이스처럼 영속성 어댑터도 한개만 만들라는 규칙은 없다. 예를 들면 영속성 연산이 필요한 도메인 클래스(DDD의 애그리거트) 하나당 하나의 영속성 어댑터를 구현할 수도 있다.
도메인 코드는 영속성 포트에 의해 정의된 명세를 어떤 클래스가 충족시키는지에 관심이 없다. 모든 포트가 구현돼 있기만 한다면 영속성 계층에서 하고 싶은 어떤 작업이든 해도 된다.
애그리거트당 하나의 영속성 어댑터 접근 방식 또한 나중에 여러 개의 바운디드 컨텍스트(bounded context)의 영속성 요구사항을 분리하기 위한 좋은 토대가 된다. 바운디드 컨텍스트 간의 경계를 명확하게 구분하고 싶다면 각 바운디드 컨텍스트가 영속성 어댑터를 하나씩 가지고 있어야 한다.
account와 관련된 서비스가 billing과 관련된 영속성 어댑터에 접근하지 않아야 한다. 경계 너머의 다른 무언가가 필요하다면 전용 인커밍 포트를 통해 접근해야 한다.
스프링 데이터 JPA 예제
앞서 살펴본 Account 클래스는 유효한 상태의 Account 엔티티만 생성할 수 있는 팩터리 메서드를 제공하고 계좌 잔고 확인 등 유효성 검증을 모든 상태 변경 메서드에서 수행하기 때문에 유효하지 않은 도메인 모델을 생성할 수 없다. 즉, 최대한 불변성을 유지하려고 한다.
1 | package buckpal.domain; |
JPA를 사용하려면 계좌의 데이터베이스 상태를 표현하는 @Entity 어노테이션이 추가된 클래스가 필요하다.
1 | package buckpal.adapter.persistence; |
1 | package buckpal.adapter.persistence; |
JPA의 @ManyToOne이나 @OneToMany 어노테이션을 이용해서 ActivityJpaEntity와 AccountJpaEntity를 연결해서 관계를 표현할 수도 있었지만 데이터베이스 쿼리에 부수효과가 생길 수 있어서 일단 제외했다.
1 | interface ActivityRepository extends JpaRepository<ActivityJpaEntity, Long> { |
스프링 부트는 이 리포지토리를 자동으로 찾고 스프링 데이터는 실제 데이터베이스와 통신하는 인터페이스 구현체를 제공한다.
1 |
|
영속성 측면과의 타협 없이 풍부한 도메인 모델을 생성하고 싶다면 도메인 모델과 영속성 모델을 매핑하는 것이 좋다.
트랜잭션 경계는 어디에 위치해야 할까?
트랜잭션은 하나의 유스케이스에 대해서 일어나는 모든 쓰기 작업에 걸쳐 있어야 한다.
가장 쉬운건 @Transactional 어노테이션을 서비스 클래스에 붙여서 모든 public 메서드를 트랜잭션으로 감싸게 하는 것이다
도메인 코드에 플러그인처럼 동작하는 영속성 어댑터를 만들면 서로 분리되서 풍부한 도메인 모델을 만들 수 있고 포트의 명세만 지켜진다면 영속성 계층 전체를 교체할 수도 있다.